Building Effective Data Lakes: A Comprehensive Guide
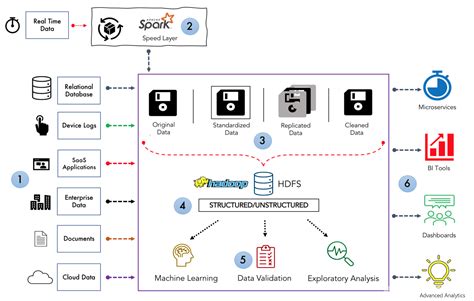
In the era of big data, organizations are seeking better ways to manage, store, and analyze large volumes of data. Data lakes have emerged as a popular solution for storing and managing massive amounts of structured and unstructured data. However, building an effective data lake requires careful planning and execution. In this guide, we will discuss the key steps and best practices for building a successful data lake that meets the needs of your organization.
- The Importance of Building an Effective Data Lake
- How to Build Effective Data Lakes: Choose the Correct Steps
- Define the Objectives and Use Cases
- Assess and Prepare Your Data
- Choose the Right Technology Stack
- Design for Scalability and Performance
- Implement Data Governance and Security
- Enable Data Discovery and Accessibility
- Implement Data Quality and Metadata Management
- Establish Monitoring and Maintenance Processes
- Conclusion
The Importance of Building an Effective Data Lake
Before diving into the details of how to build an effective data lake, it's important to understand why a data lake is important for modern organizations. Data lakes offer a centralized repository for storing all types of data, from structured data in databases to unstructured data in the form of text documents, images, and videos. This enables organizations to break down data silos and gain a holistic view of their data, leading to better decision-making and actionable insights.
How to Build Effective Data Lakes: Choose the Correct Steps
Building an effective data lake involves a series of critical steps that must be carefully considered and executed. By following the right steps, organizations can ensure that their data lake meets their specific needs and delivers value to the business. Below are the key steps to consider when building an effective data lake:
Define the Objectives and Use Cases
The first step in building an effective data lake is to clearly define the objectives and use cases for the data lake. It's important to align the data lake strategy with the business goals and identify the specific use cases that the data lake will support. This may include use cases such as advanced analytics, machine learning, reporting, and data exploration. By understanding the business objectives, organizations can design a data lake that meets the specific needs of the business.
Assess and Prepare Your Data
Once the objectives and use cases have been defined, the next step is to assess and prepare the data that will be ingested into the data lake. This involves understanding the different types of data that exist within the organization, including structured, semi-structured, and unstructured data. Organizations should also assess the quality of the data and identify any data cleansing or transformation that may be required before ingestion. By preparing the data upfront, organizations can ensure that the data lake is populated with high-quality, reliable data.
Choose the Right Technology Stack
One of the critical decisions in building an effective data lake is choosing the right technology stack. The technology stack should be selected based on the specific requirements of the organization, including factors such as data volume, velocity, variety, and the skill sets of the IT team. Common technologies used in building data lakes include Apache Hadoop, Apache Spark, Amazon S3, and Microsoft Azure Data Lake Storage. It's important to evaluate different technologies and choose the stack that best aligns with the organization's needs.
Design for Scalability and Performance
Scalability and performance are key considerations when building a data lake, especially as organizations are dealing with ever-increasing data volumes. The data lake architecture should be designed for scalability, enabling it to handle growing data volumes without compromising performance. This may involve leveraging distributed computing and storage technologies, such as Hadoop Distributed File System (HDFS) and cloud-based storage solutions. By designing for scalability and performance, organizations can future-proof their data lakes and support the growing demands of the business.
Implement Data Governance and Security
Data governance and security are critical considerations for any data management initiative, and building a data lake is no exception. Organizations need to establish robust data governance processes to ensure that data is managed in a compliant and responsible manner. This may include defining data ownership, access controls, and data retention policies. In addition, organizations must implement strong security measures to protect the data lake from unauthorized access and data breaches. By implementing data governance and security, organizations can build trust in the data lake and ensure that data is handled in a secure and compliant manner.
Enable Data Discovery and Accessibility
An effective data lake should enable easy and efficient data discovery and accessibility for end users. This involves providing tools and capabilities that allow users to easily search for and access the data they need. Organizations can achieve this by implementing data cataloging and metadata management solutions that provide a comprehensive view of the data assets within the data lake. Additionally, organizations should provide self-service analytics capabilities that empower users to explore and analyze the data on their own. By enabling data discovery and accessibility, organizations can maximize the value of the data lake and empower users to make data-driven decisions.
Implement Data Quality and Metadata Management
Ensuring the quality and reliability of the data within the data lake is essential for deriving meaningful insights and making informed decisions. Organizations should implement data quality and metadata management processes to maintain the accuracy, consistency, and completeness of the data. This may involve implementing data profiling and cleansing tools, as well as establishing data stewardship roles and responsibilities. By implementing data quality and metadata management, organizations can ensure that the data within the data lake is of high quality and can be trusted for decision-making purposes.
Establish Monitoring and Maintenance Processes
Finally, building an effective data lake requires ongoing monitoring and maintenance processes to ensure that the data lake continues to meet the needs of the organization. This involves establishing key performance indicators (KPIs) and implementing monitoring tools that provide visibility into the health and performance of the data lake. Organizations should also establish regular maintenance and optimization processes to address any issues and ensure that the data lake remains efficient and effective. By establishing monitoring and maintenance processes, organizations can ensure that the data lake continues to deliver value to the business in the long term.
Conclusion
Building an effective data lake requires careful planning and execution, taking into consideration the specific needs and objectives of the organization. By following the key steps outlined in this guide, organizations can build a data lake that meets the demands of modern data management and analytics, enabling them to leverage data as a strategic asset for better decision-making and competitive advantage.
Learn More :
 The Top Payoff is Aligning Unstructured with Structured Data
24 January 2024 by Admin
The Top Payoff is Aligning Unstructured with Structured Data
24 January 2024 by Admin
In today's data-driven world, organizations are constantly searching for ways to extract valuable insights from the vast amounts of data they collect. This has led to an increased focus on both struct...
 The History of Big Data
24 January 2024 by Admin
The History of Big Data
24 January 2024 by Admin
In today's digital age, big data plays a crucial role in almost every aspect of our lives. From business and healthcare to education and government, the impact of big data is undeniable. But how did t...
 Understanding How Big Data Works
24 January 2024 by Admin
Understanding How Big Data Works
24 January 2024 by Admin
Big data is a term used to describe large and complex data sets that are difficult to process using traditional data management tools. These data sets come from a variety of sources, including social ...
 The Challenges of Big Data in Today's Information Age
24 January 2024 by Admin
The Challenges of Big Data in Today's Information Age
24 January 2024 by Admin
As we enter the era of big data, we are confronted with a new set of challenges that come with the massive amount of information being generated and stored every day. The term 'big data' refers to the...
 The Power of Big Data Works Integration
24 January 2024 by Admin
The Power of Big Data Works Integration
24 January 2024 by Admin
Big data has become an essential part of modern business operations, offering valuable insights and opportunities for growth. However, to fully harness the power of big data, it is essential to integr...
 Big Data Works Manage: Why It's Crucial for Businesses
24 January 2024 by Admin
Big Data Works Manage: Why It's Crucial for Businesses
24 January 2024 by Admin
Big data has become an integral part of modern business operations. With the increasing volume of data being generated and collected by businesses, it has become crucial to have effective big data wor...
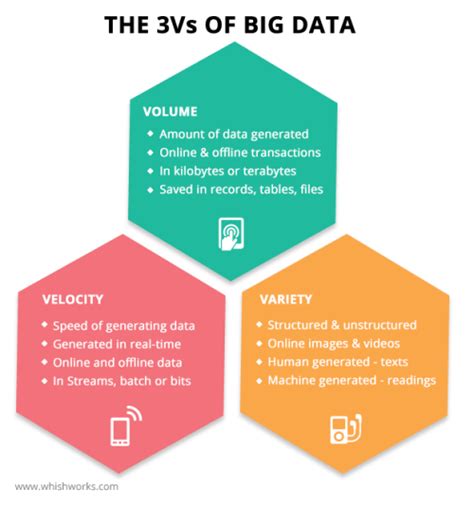 The Three Vs of Big Data
24 January 2024 by Admin
The Three Vs of Big Data
24 January 2024 by Admin
Big data has become a critical part of business and technology in the modern world. With the advent of new technologies and the increase in digital data, the importance of understanding and harnessing...
 The Definition of Big Data
24 January 2024 by Admin
The Definition of Big Data
24 January 2024 by Admin
Big data is a term that refers to extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions. T...
 Aligning Big Data with Specific Business Goals
24 January 2024 by Admin
Aligning Big Data with Specific Business Goals
24 January 2024 by Admin
In today's digital age, businesses are constantly generating vast amounts of data from various sources such as social media, customer transactions, and IoT devices. This influx of big data presents bo...
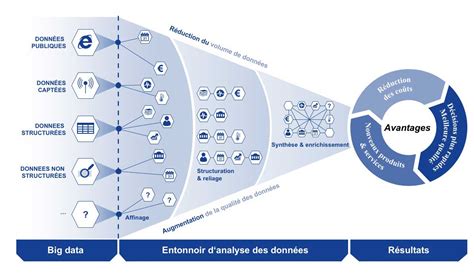 The Power of Big Data: How It Works and the Importance of Analyzing It
24 January 2024 by Admin
The Power of Big Data: How It Works and the Importance of Analyzing It
24 January 2024 by Admin
Big data has become a buzzword in the business world, and for good reason. With the exponential growth of digital information in recent years, organizations are now able to collect and analyze vast am...
 The Value and Truth of Big Data
24 January 2024 by Admin
The Value and Truth of Big Data
24 January 2024 by Admin
Big data has become an integral part of our modern world, impacting nearly every industry and aspect of our lives. With the vast amount of information generated and collected every day, big data has t...
 The Benefits of Big Data
24 January 2024 by Admin
The Benefits of Big Data
24 January 2024 by Admin
In today's digital age, data is being produced at an unprecedented rate. This explosion of data has given rise to the concept of big data, which refers to extremely large datasets that can be analyzed...
 Exploring Big Data Use Cases
24 January 2024 by Admin
Exploring Big Data Use Cases
24 January 2024 by Admin
As the world becomes increasingly digitized, the amount of data being generated is growing at an exponential rate. This large volume of data, often referred to as big data, comes from various sources ...
 Big Data Best Practices
24 January 2024 by Admin
Big Data Best Practices
24 January 2024 by Admin
Big data has become an integral part of many organizations, enabling them to gather, store, and analyze vast amounts of data to gain insights and make informed decisions. However, managing big data co...
 Plan Your Discovery Lab for Performance
24 January 2024 by Admin
Plan Your Discovery Lab for Performance
24 January 2024 by Admin
When it comes to improving performance in any field, a discovery lab can be an invaluable tool. Whether you're looking to enhance the performance of your employees, optimize a manufacturing process, o...
 The Importance of Standards and Governance in Easing Skills Shortage
24 January 2024 by Admin
The Importance of Standards and Governance in Easing Skills Shortage
24 January 2024 by Admin
In today's global economy, the demand for skilled workers is higher than ever. However, many countries are facing a skills shortage, making it difficult for businesses to find the talent they need to ...
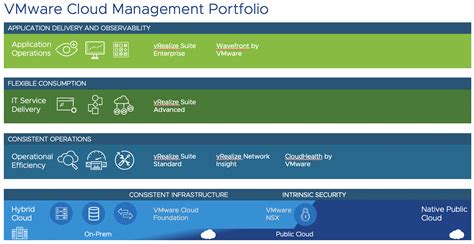 Align with the Cloud Operating Model
24 January 2024 by Admin
Align with the Cloud Operating Model
24 January 2024 by Admin
In today's digital world, businesses are increasingly turning to cloud computing to support their operations and drive innovation. The cloud operating model offers a range of benefits, including scala...
 The Fascinating World of Machine Learning
24 January 2024 by Admin
The Fascinating World of Machine Learning
24 January 2024 by Admin
Machine learning is a field of computer science that allows computers to learn and improve from experience without being explicitly programmed. It is a subset of artificial intelligence (AI) that focu...
 The Importance of Product Development in Today's Business Environment
24 January 2024 by Admin
The Importance of Product Development in Today's Business Environment
24 January 2024 by Admin
Product development is a crucial aspect of any business's success in today's highly competitive marketplace. It involves a series of steps that companies take to bring a new product or service to the ...
